https://doi.org/10.35381/i.p.v8i14.4885
Asistente conversacional basado en LLM para recomendaciones técnicas en el cultivo de banano
LLM-Based conversational assistant for technical recommendations in banana cultivation
Gabriel Emilio García-Mazón
Universidad Técnica de Machala, Machala, El Oro
Ecuador
https://orcid.org/0000-0001-5066-7370
Bryan Steve Moreno-Morocho
Universidad Técnica de Machala, Machala, El Oro
Ecuador
https://orcid.org/0000-0001-7035-753X
Wilmer Rivas-Asanza
Universidad Técnica de Machala, Machala, El Oro
Ecuador
https://orcid.org/0000-0002-2239-3664
Eduardo Tusa-Jumbo
Universidad Técnica de Machala, Machala, El Oro
Ecuador
https://orcid.org/0000-0002-9408-5134
Revisado: 08 de octubre 2025
Aprobado: 15 de diciembre 2025
Publicado: 01 de enero 2026
RESUMEN
Este trabajo consistió en desarrollar un asistente conversacional para brindar recomendaciones técnicas sobre el cultivo de banano ante la limitada asistencia disponible para pequeños productores. Se aplicó la metodología CRISP-DM para el desarrollo y se empleó un enfoque de recuperación de información y generación de respuestas sustentado en un modelo de lenguaje, con integración a Telegram para interacción por texto y voz, almacenamiento del historial de diálogo y consulta a un corpus de 61 documentos técnicos oficiales de instituciones latinoamericanas. Los resultados se obtuvieron mediante una encuesta a 13 especialistas agronómicos con criterios de experiencia de usuario, en la que se registró una valoración media alta y una aceptación completa en aplicabilidad, delimitación del dominio, memoria conversacional y usabilidad, además de una aceptación elevada en validez técnica y claridad. En conclusión, el asistente mostró factibilidad para apoyar buenas prácticas fitosanitarias, dejando la posibilidad para extenderse a otros cultivos.
Descriptores: Agricultura; cultivo; banano; inteligencia artificial; recuperación de información. (Tesauro UNESCO).
ABSTRACT
This work consisted of developing a conversational assistant to provide technical recommendations for banana cultivation in response to the limited technical assistance available to small producers. The CRISP-DM methodology was applied for development, and an approach combining information retrieval and response generation supported by a language model was used, with integration into Telegram for text and voice interaction, storage of dialogue history, and consultation of a corpus of 61 official technical documents from Latin American institutions. The results were obtained through a survey of 13 agronomy specialists using user experience criteria, which reported a high mean rating and full acceptance regarding applicability, domain delimitation, conversational memory, and usability, as well as high acceptance in technical validity and clarity. In conclusion, the assistant proved feasible for supporting good phytosanitary practices, with the possibility of being extended to other crops.
Descriptors: Agriculture; crop; banana; artificial intelligence; information retrieval. (UNESCO Thesaurus).
INTRODUCCIÓN
El acceso limitado a la asesoría técnica especializada sigue siendo una barrera estructural para una gran parte de pequeños productores agrícolas en América Latina, especialmente en cultivos estratégicos como el banano (Becerra-Encinales et al., 2024; Boros et al., 2025). En Ecuador la cobertura y calidad de los servicios de extensión agraria, continúa siendo insuficiente y poco inclusiva, lo que restringe el acompañamiento técnico oportuno para los productores (Guamán-Rivera, 2022). Esta carencia afecta la adopción de buenas prácticas agronómicas, el control de enfermedades y la sostenibilidad del cultivo, particularmente frente a amenazas como la Sigatoka negra y el marchitamiento por Fusarium R4T (Esguera et al., 2024; Munhoz et al., 2024; Romero-García et al., 2025).
La carencia de orientación técnica pertinente y actualizada plantea un reto que debe atenderse a través de estrategias novedosas e innovadoras. En este escenario, la inteligencia artificial (IA), en particular los modelos de lenguaje y los agentes conversacionales, han emergido como tecnologías disruptivas que convierten repositorios documentales dispersos en respuestas trazables y contextuales, ampliando el acceso al conocimiento técnico y acelerando el aprendizaje situado en campo (Caffaro y Rizzo, 2024; Klesel y Wittmann, 2025; Kuska et al., 2024).
En el sector agrícola, los chatbots basados en procesamiento de lenguaje natural permiten consultas en cualquier momento, lugar y desde canales familiares como WhatsApp, se ajustan a diferentes perfiles de usuarios y emplean un lenguaje accesible (incluidos usuarios con baja alfabetización digital y lenguas locales), por lo que se perfilan como alternativas viables para reforzar y escalar los servicios de extensión tradicionales (Calvo-Valverde et al., 2023; Coggins et al., 2025; Lubawa et al., 2025). Diversos estudios respaldan su utilidad práctica; el chatbot "Agriculture TalkBot" atendió consultas de agricultores mediante comandos de voz, mejorando su capacidad de respuesta ante plagas y problemas del cultivo (Ariyo Okaiyeto et al., 2025). En Kenia, un sistema similar brindó asesoría a productores de papa, elevando notablemente la eficiencia y satisfacción de los usuarios (Korir et al., 2023). ChatGPT también fue evaluado con cultivadores de arroz en Nigeria, donde sus respuestas superaron en completitud y utilidad a las de técnicos de extensión agrícola (Ibrahim et al., 2024). Por su parte, Farmer.Chat, un sistema multilingüe basado en modelos de lenguaje de gran tamaño (LLM) impulsados por inteligencia artificial generativa, procesó más de 300 000consultas en cuatro países e influyó positivamente en las decisiones de más de 15 000 agricultores (Singh et al., 2024).
En la práctica, muchos prototipos y despliegues de chatbots agrícolas se han construido sobre plataformas comerciales cerradas, como Google Dialogflow, IBM Watson Assistant, Amazon Lex/AWS Bedrock y Azure Bot Service con modelos en Azure OpenAI, lo que limita la personalización local y plantea interrogantes sobre gobernanza, seguridad y control de datos en entornos de nube (Calvo-Valverde et al., 2023; Korir et al., 2023; Sapkota et al., 2025). Por otra parte, los LLMs de propósito general (ChatGPT, Gemini, otros), no tienen acceso a conocimiento técnico especializado y suelen generar información inexacta o con riesgos de alucinación o desajuste contextual; esto reduce su confiabilidad para asistencia agronómica práctica (Lewis et al., 2021; Peñalver-Higuera et al., 2025; Singh et al., 2024). Las soluciones basadas en aplicaciones móviles y servicios SMS, presentan restricciones en la profundidad y adaptabilidad de la interacción, lo que limita la personalización de recomendaciones, reduce la capacidad de respuesta ante contextos cambiantes y, en consecuencia, conduce a efectos heterogéneos y frecuentemente modestos sobre el desempeño productivo (Spielman et al., 2021).
La técnica de Generación Aumentada por Recuperación (RAG) representa un método que optimiza la precisión, confiabilidad y trazabilidad de los sistemas basados en modelos de lenguaje, debido a que permite que las respuestas generadas estén fundamentadas en documentación técnica verificable. Este enfoque permite que el modelo recupere información de fuentes externas (guías técnicas, manuales, reportes, artículos científicos) antes de formular su respuesta, reduciendo errores y alucinaciones (Lewis et al., 2021). Implementar modelos LLM abiertos como DeepSeek V3, en combinación con repositorios locales y datos propietarios, ofrece mayor control, capacidad de ajuste al contexto agronómico particular y protección de la privacidad de los usuarios (Samuel et al., 2025).
En el sector agrícola, los productores pueden formular consultas por voz desde el campo y recibir respuestas sin la necesidad de escribir directamente, lo que mejora la usabilidad en entornos con baja alfabetización digital; esto es posible con una herramienta de reconocimiento automático de voz, como Whisper utilizada en el flujo del asistente conversacional. Whisper es un modelo de OpenAI entrenado con ~ 680 000 horas de audio supervisado y cobertura de 96 idiomas, lo que facilita transcripciones estables ante ruido ambiental, acentos y vocabulario técnico especializado (Graham y Roll, 2024; Radford et al., 2022).
En este trabajo se presenta el diseño e implementación de un asistente conversacional para el sector bananero que democratiza el acceso a recomendaciones técnicas y refuerza el manejo fitosanitario en pequeños productores. El sistema funciona en Telegram (texto y audio) y se sustenta en una arquitectura RAG sobre el LLM DeepSeek-V3; emplea FAISS y el modelo multilingual-e5-large-instruct para la indexación y búsqueda semántica de un corpus técnico curado, conserva memoria conversacional en MongoDB, integra transcripción de voz con Whisper y es orquestado mediante LangChain siguiendo la metodología CRISP-DM. La solución se expone como API RESTful, mantiene coherencia temática durante el diálogo y se apoya en documentación oficial del Ministerio de Agricultura de Ecuador, Agrocalidad y organismos internacionales latinoamericanos.
Por tanto el objetivo de la investigación es desarrollar un asistente conversacional para brindar recomendaciones técnicas sobre el cultivo de banano ante la limitada asistencia disponible para pequeños productores.
MÉTODO
El proyecto se llevó a cabo utilizando la metodología CRISP-DM (Cross-Industry Standard Process for Data Mining), seleccionada por su fortaleza y versatilidad en proyectos de inteligencia artificial y ciencia de datos. Este marco de trabajo permitió organizar el desarrollo en seis fases, las cuales se contextualizaron a los requerimientos del sector agrícola y la arquitectura RAG propuesta.
Los Modelos de Lenguaje de Gran Tamaño (LLMs) presentan limitaciones intrínsecas, tales como las alucinaciones, conocimiento desactualizado y la poca transparencia en sus procesos de razonamiento (Gao et al., 2023). Para operar bajo estas restricciones y garantizar la fiabilidad necesaria en el cultivo de banano, se implementó la arquitectura de Generación Aumentada por Recuperación (RAG). Este método combina modelos de lenguaje generativos con mecanismos para recuperar información, lo cual posibilita que el sistema fundamente sus respuestas en datos adquiridos a partir de fuentes externas y verificadas (Gupta et al., 2024).
La Figura 1 presenta el funcionamiento del sistema. El proceso inicia con una base de conocimiento compuesta por archivos PDF, la cual se procesa e indexa en una base de datos vectorial. Cuando se recibe una consulta, ya sea en texto o en audio transcrito por el modelo Whisper, el sistema la convierte en un embedding y recupera los fragmentos de información más relevantes.
Adicionalmente, se integró un componente de memoria conversacional que permite recuperar los últimos ocho mensajes del diálogo para mantener la coherencia temática durante la interacción. Finalmente, el modelo DeepSeek-V3 genera la respuesta utilizando la consulta del usuario, los documentos recuperados y el historial de la conversación. La orquestación integral de este flujo es gestionada por el framework LangChain.
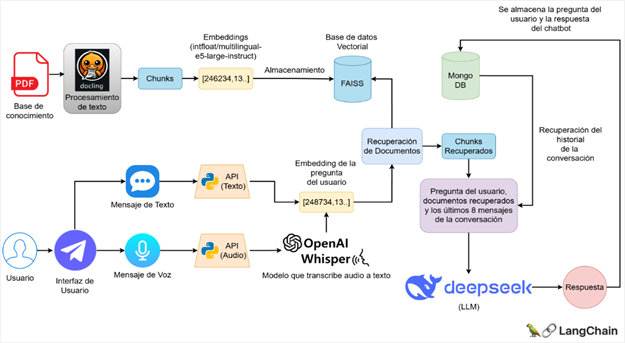
Figura 1. Arquitectura del chatbot basado en RAG.
Elaboración: Los autores.
A continuación, se describen las actividades desarrolladas en cada fase de la metodología CRISP-DM.
Fase 1. Comprensión del negocio
En esta fase se delimitó el alcance del proyecto dentro de la industria bananera de Ecuador. En la actualidad, numerosos trabajadores y agricultores del sector no tienen acceso inmediato a sugerencias técnicas fiables que apoyen sus decisiones agronómicas. Por consiguiente, el sistema se orientó a proporcionar soporte especializado durante todo el ciclo productivo, con el fin de asegurar un asesoramiento contextualizado en buenas prácticas agronómicas.
Fase 2. Comprensión de los datos
En esta fase se recopilaron documentos técnicos sobre buenas prácticas para el cultivo de banano. La búsqueda se restringió a fuentes oficiales de Ecuador y Latinoamérica, incluyendo manuales, guías e informes de entidades como el Ministerio de Agricultura y Ganadería (MAG), Agrocalidad y el Instituto Nacional de Investigaciones Agropecuarias (INIAP). Se seleccionaron un total de 61 documentos. Este conjunto de archivos forma la base de conocimiento que utiliza el sistema para responder a las consultas sobre el manejo del cultivo de banano.
Fase 3. Preparación de los datos
La biblioteca Docling permitió la extracción del contenido textual de los archivos PDF. Posteriormente se implementó una estrategia de segmentación jerárquica que aplica inicialmente recursive chunking para preservar la estructura de los párrafos y recurre al token chunking únicamente cuando los segmentos exceden el límite de entrada del modelo de generación de embeddings intfloat/multilingual-e5-large-instruct. Para garantizar la densidad informativa se filtraron los fragmentos inferiores a 25 palabras y aquellos correspondientes a índices. Finalmente, se ejecutó un proceso de sanitización para eliminar caracteres especiales y símbolos ajenos al idioma. De este modo, se obtuvieron chunks limpios y estructurados, listos para ser transformados en representaciones vectoriales (embeddings) para su almacenamiento en la base de datos vectorial del sistema. El proceso descrito se muestra en la Figura 2.
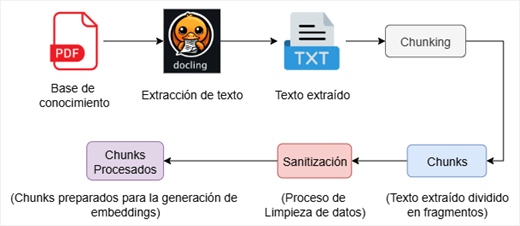
Figura 2. Proceso de limpieza y preparación de los datos.
Elaboración: Los autores.
Fase 4. Modelado
Esta fase comprendió la implementación del núcleo técnico del chatbot fundamentado en la arquitectura RAG (Figura 3). El diseño se estructura en dos flujos principales: la indexación de documentos en la base de datos vectorial y el proceso de recuperación y generación, el cual integra capacidades de interacción por voz y memoria conversacional.
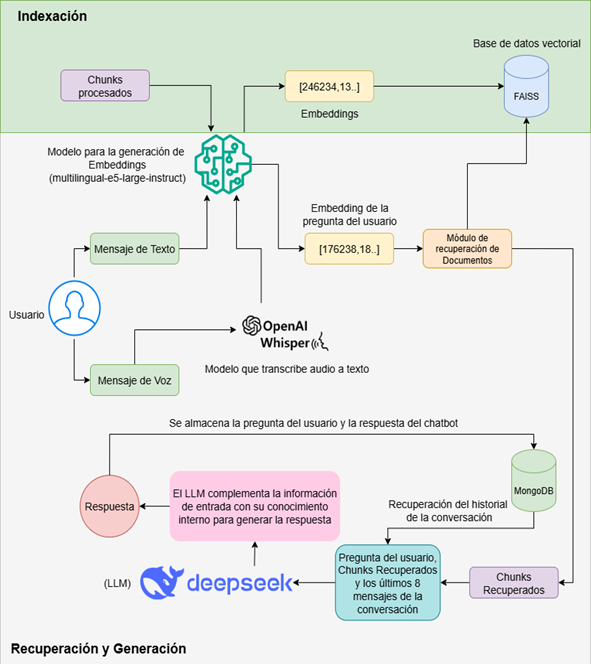
Figura 3. Indexación, flujo de recuperación y generación.
Elaboración: Los autores.
Indexación de la base de conocimiento
A partir de los fragmentos de texto obtenidos en la fase de preparación de datos, se generaron vectores numéricos (embeddings) utilizando el modelo de código abierto multilingual-e5-large-instruct. Posteriormente, estos vectores se indexaron en la base de datos vectorial FAISS, la cual permite realizar búsquedas basadas en similitud semántica, facilitando la recuperación eficiente y precisa de información relevante.
Flujo de recuperación y generación
El flujo inicia con la entrada del usuario. Si se trata de texto, el modelo multilingual-e5-large-instruct genera directamente su embedding. Si el mensaje es de voz, el sistema utiliza el modelo Whisper de OpenAI para convertir el audio en texto y, a partir de esa transcripción, se crea su embedding.
A partir del embedding generado, se recuperan los 20 documentos con mayor similitud semántica respecto a la consulta del usuario en la base de datos vectorial. A dicho conjunto se le aplica un reordenamiento (reranking) que evalúa dos factores: la relevancia semántica (con un peso del 80%) y la calidad del contenido (con un peso del 20%), medida por la densidad de información y la extensión del texto. De este proceso se obtienen los cinco documentos con mayor puntaje, que representan la información más relevante para la generación de una respuesta fundamentada.
Simultáneamente, se consulta la base de datos MongoDB para recuperar el historial de la conversación. Se utilizó una ventana de contexto limitada a los últimos ocho mensajes (cuatro interacciones) para mantener el hilo de la conversación sin superar el límite de tokens del modelo.
Finalmente, el modelo DeepSeek-V3 recibe la pregunta del usuario, los cinco documentos recuperados y el historial de la conversación para formular la respuesta. Al terminar el proceso, tanto la consulta del usuario como la respuesta del chatbot se guardan en MongoDB, actualizando así el historial de la conversación para futuras interacciones.
Se establecieron pautas específicas en el system prompt del LLM con el fin de regular el comportamiento, la estructura y el contenido de las respuestas que produce el chatbot. La Tabla 1 detalla estas instrucciones y su función.
Tabla 1.
Directrices definidas en el system prompt para el control del comportamiento del chatbot.
|
Directriz del Prompt (System Prompt) |
Propósito de la directriz |
|
Tema específico: Asegúrate de que la pregunta esté relacionada con el cultivo del banano antes de responder. Si no lo está, responde con algo como: “Este asistente está diseñado solo para responder preguntas sobre el cultivo del banano.” |
Delimitar las respuestas del chatbot al ámbito del cultivo de banano, evitando responder fuera del alcance definido. |
|
Integra conocimientos: Usa los documentos como base principal, pero intenta aportar detalles útiles desde tu conocimiento general. |
Permitir al LLM combinar la información recuperada de los documentos con su conocimiento interno para ofrecer respuestas más completas. |
|
Sé útil y claro: Explica las cosas con palabras sencillas. Imagina que hablas con un agricultor que quiere entender bien qué hacer, sin tecnicismos. |
Asegurar la comprensibilidad de las respuestas para el público objetivo mediante el uso de un lenguaje accesible. |
|
Organiza la respuesta: Si es posible, usa pasos, listas o ejemplos que ayuden a entender mejor tu explicación y que faciliten la acción. Haz que la respuesta sea fácil de aplicar. |
Orientar al LLM para que organice las respuestas de forma lógica y accionable, lo que ayuda a integrar y aplicar las sugerencias. |
|
Complementa con tu conocimiento: Si los documentos no tienen toda la información necesaria, puedes usar lo que sabes como modelo entrenado. |
Permitir al modelo emplear su conocimiento base cuando la información recuperada no sea suficiente para generar una respuesta completa y fiable. |
|
Sé honesto: Si no tienes información suficiente para dar una respuesta confiable, indícalo de forma clara y respetuosa. |
Instruir al chatbot a reconocer sus limitaciones cuando no puede ofrecer una respuesta exacta, para instaurar un comportamiento fiable y ético. |
|
Formato de respuesta: No uses encabezados como # o ###. Puedes usar negrita (**texto**), cursiva (*texto*) y saltos de línea (\n) para mejorar la claridad. Evita cualquier otro formato. |
Adaptar el formato de salida a las capacidades de renderizado de Telegram, asegurando la legibilidad y experiencia del usuario en la plataforma. |
Elaboración: Los autores.
Fase 5. Evaluación
Para medir el nivel de aceptación del chatbot se diseñó un cuestionario en Microsoft Forms (Tabla 2). La estructura del instrumento se basó en métricas de interfaz y experiencia de usuario (UI/UX) propuestas por Kim et al. (2024).
Se analizaron siete dimensiones para determinar la aceptación del asistente: la exactitud técnica de las respuestas, la utilidad práctica de las recomendaciones, la claridad del lenguaje, la restricción al dominio del banano, la fidelidad de la transcripción de voz, el funcionamiento de la memoria conversacional y la facilidad de uso en Telegram.
Tabla 2.
Preguntas para evaluar el nivel de aceptación del chatbot.
|
ID |
Preguntas de cuestionario para expertos |
|
¿La información proporcionada por el chatbot es técnicamente correcta según sus conocimientos en agronomía? |
|
|
P2 |
Considerando su criterio profesional, ¿las recomendaciones del chatbot son aplicables en el manejo práctico del cultivo de banano? |
|
P3 |
¿El chatbot utiliza un lenguaje claro y sencillo, adecuado para ser comprendido por agricultores? |
|
P4 |
Cuando se le hacen preguntas no relacionadas con el cultivo del banano, ¿el chatbot responde de forma adecuada, explicando que su conocimiento se limita al cultivo de banano? |
|
P5 |
¿Las transcripciones de voz realizadas por el chatbot son suficientemente precisas para comprender la consulta realizada por el usuario? |
|
P6 |
¿El chatbot mantiene la continuidad de la conversación recordando el contexto anterior de las últimas interacciones? |
|
P7 |
¿La interacción con el chatbot en Telegram le resultó intuitiva y fácil de usar? |
Elaboración: Los autores.
La evaluación contó con la participación de 13 especialistas en agronomía enfocados en el cultivo de banano. Este grupo probó la herramienta y emitió su valoración mediante una escala de Likert de cinco niveles, donde el valor 1 corresponde a "Totalmente en desacuerdo" y el 5 a "Totalmente de acuerdo".
Fase 6. Despliegue
El sistema fue expuesto como un servicio web mediante una API RESTful (Figura 4). Esta estrategia facilita la integración con diversos canales de interacción, lo que le otorga al sistema flexibilidad y escalabilidad. Se definieron dos endpoints: /chat para el procesamiento de texto y /audio para mensajes de voz. Para asegurar la estabilidad del sistema se limitó el procesamiento de voz a mensajes de máximo 30 segundos. Si el audio supera esta duración, el chatbot omite la transcripción y envía una respuesta automática para informar al usuario sobre la restricción.
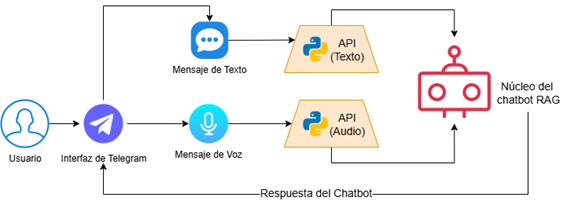
Figura 4. Diagrama de despliegue del chatbot.
Elaboración: Los autores.
Se seleccionó Telegram como interfaz de usuario. Esta plataforma se utilizó debido a la disponibilidad de la herramienta BotFather, la cual simplifica la creación de bots sin requerir procesos de verificación complejos. Asimismo, se consideró su nivel de adopción en el contexto ecuatoriano.
El intercambio de mensajes entre el usuario y el chatbot se realiza mediante solicitudes HTTP POST. Cuando el usuario envía una consulta desde Telegram, la API recibe la información y activa el procesamiento interno del sistema RAG. Finalmente, la respuesta generada es enviada de regreso al usuario a través del mismo canal de mensajería.
RESULTADOS
A continuación, los resultados se organizan en: (a) verificación funcional del asistente conversacional, (b) memoria y continuidad temática y (c) valoración del chatbot por especialistas. La evidencia cualitativa y cuantitativa se respalda con tablas y figuras referenciadas en el texto para una lectura precisa y ordenada.
Verificación funcional del asistente conversacional
La verificación funcional del asistente conversacional se evidencia en tres frentes: primero, la Figura 5 presenta su identidad y publicación en Telegram, canal seleccionado por su amplia adopción local y soporte nativo para bots.
Figura 5. Publicación del chatbot e interfaz en Telegram.
Elaboración: Los autores.
Segundo, la Figura 6 documenta un ejemplo de la conversación por texto (consulta–respuesta), en el que se aprecia un tono claro, orientado a la acción y adecuado.
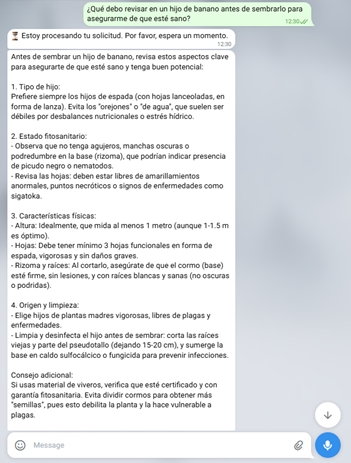
Figura 6. Interacción por texto (consulta–respuesta).
Elaboración: Los autores.
Adicionalmente, se puede interactuar a través de voz, donde el sistema recibe el audio, lo transcribe automáticamente y emite la respuesta, aplicando un límite de 30 segundos por mensaje para preservar la fluidez y la disponibilidad del servicio, con notificación adecuada al usuario cuando se excede dicho umbral.
Memoria y continuidad temática
La memoria conversacional mantiene la continuidad temática entre turnos, recuperando el contexto inmediato para resolver referencias y dar respuestas consistentes sin repetir información. El chatbot enlaza una nueva consulta con datos previos, y muestra la persistencia del hilo al ampliar y precisar recomendaciones en mensajes subsecuentes.
Valoración del chatbot por especialistas
Para evaluar la aceptación del chatbot se diseñó un cuestionario de preguntas, con una valoración basada en escala de Likert de 5 niveles por pregunta, donde: 1 = “Totalmente en desacuerdo”, 2 = “En desacuerdo”, 3 = “Ni de acuerdo ni en desacuerdo”, 4 = “De acuerdo” y 5 = “Totalmente de acuerdo”.
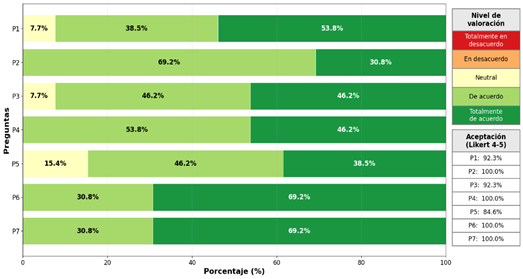
Figura 7. Distribución porcentual por pregunta.
Elaboración: Los autores.
En la Figura 7, se muestra la distribución porcentual por pregunta, teniendo en cuenta las dos escalas más altas de Likert (4 = “De acuerdo” y 5 = “Totalmente de acuerdo”). Se obtuvieron los siguientes resultados: un 92.3% en validez técnica (P1) y en claridad (P3); un 84.6% en precisión de transcripción de voz (P5); y, un 100% en aplicabilidad (P2), delimitación de dominio (P4), memoria conversacional (P6) y usabilidad en Telegram (P7).
Por último en la figura 8 se muestra el análisis de medias con intervalos de confianza al 95%, evidencia una alta aceptación del chatbot, con todas las puntuaciones situadas por encima de “De acuerdo” (≥4 en escala Likert 1–5).
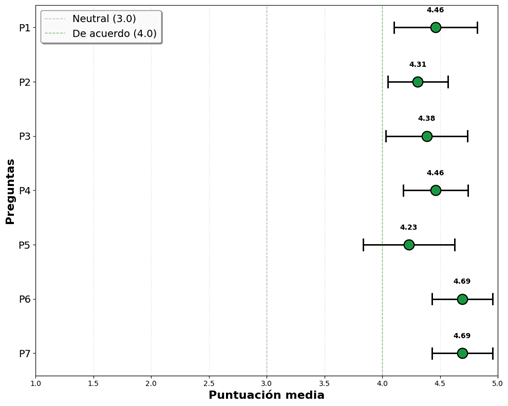
Figura 8. Medias por pregunta con intervalos de confianza al 95%.
Elaboración: Los autores.
Los mejores desempeños corresponden a memoria/continuidad conversacional (P6) y usabilidad en Telegram (P7), ambas con 4,69, y con intervalos estrechos completamente por encima del umbral de 4, lo que denota consistencia. La corrección técnica (P1) y el manejo de preguntas fuera de dominio (P4) alcanzan 4,46, confirmando solidez metodológica y adecuada delimitación del sistema. La claridad del lenguaje (P3, 4,38) y la aplicabilidad práctica (P2, 4,31) muestran valoración favorable, aunque con mayor dispersión. La dimensión relativamente más débil es la transcripción de voz (P5, 4,23), cuyo límite inferior del IC95% se aproxima a 4, sugiriendo oportunidades de mejora en robustez frente a ruido, acentos y variación léxica.
DISCUSIÓN
Se cumplió con el objetivo propuesto al desarrollar un asistente conversacional RAG con DeepSeek-V3, FAISS, memoria en MongoDB y entrada multimodal (texto/voz con Whisper) operativo en Telegram y orquestado con LangChain. Las pruebas realizadas demostraron un correcto cumplimiento de las funcionalidades del chatbot, tales como la claridad y exactitud de las respuestas, la transcripción de audio a texto y la memoria conversacional. En la valoración experta (n=13), los resultados se consolidan por dos vías:
1. métricas de tendencia central con media global de 4,46/5 y puntajes sobresalientes en memoria y usabilidad (4,69/5), seguidos de validez técnica y delimitación de dominio (4,46/5); y
2. distribución porcentual de Aceptación (Likert 4–5), con 100% en: aplicabilidad (P2), límite de dominio (P4), memoria (P6) y usabilidad (P7); 92,3% en validez técnica (P1) y claridad (P3); y, 84,6% en transcripción de voz (P5). Esto confirma la pertinencia del chatbot como una herramienta de apoyo a la decisión en campo, al proporcionar recomendaciones en buenas prácticas agrícolas aplicadas al sector bananero.
Estos hallazgos se alinean con la literatura reciente: RAG eleva precisión y trazabilidad al anclar las respuestas en fuentes verificadas (Lewis et al., 2021); en agricultura, los agentes conversacionales mejoran acceso a conocimiento y escala de atención (Calvo-Valverde et al., 2023); y Whisper aporta accesibilidad multimodal con reconocimiento robusto (Radford et al., 2022). La elección de DeepSeek-V3 permite explorar un LLM abierto y competitivo, coherente con enfoques de disponibilidad amplia y adaptación local (Ariyo Okaiyeto et al., 2025).
En conjunto, la arquitectura RAG con DeepSeek-V3, la memoria conversacional y la interfaz en Telegram demuestran solidez técnica y pertinencia práctica para el asesoramiento agronómico del banano, sentando bases para escalar el servicio, incorporar nuevas guías regionales y extenderlo a otros cultivos con indicadores de adopción e impacto productivo.
CONCLUSIONES
Se desarrolló un chatbot integrado con API REST a Telegram, para dar recomendaciones de buenas prácticas agrícolas aplicadas para el cultivo de banano. Tiene una arquitectura RAG implementada con LLM DeepSeek-V3, FAISS, memoria en MongoDB y entrada multimodal (texto/voz con Whisper). Fue orquestado con LangChain, y todo el proceso guiado por la metodología CRISP-DM. Las pruebas de ejecución evidenciaron que el chatbot cumple satisfactoriamente con sus funciones (ofrece respuestas claras y precisas, realiza la conversión de audio a texto con fiabilidad y mantiene la memoria conversacional).
La valoración de expertos se realizó aplicando una encuesta a 13 especialistas, diseñada con métricas UI/UX y escala de Likert (1-5). La puntuación media global fue de 4,46/5, con picos en memoria y usabilidad (4,69/5) y, solidez en validez técnica y delimitación de dominio (4,46/5). En términos de distribución, teniendo en cuenta las dos escalas más altas de Likert (4 = “De acuerdo” y 5 = “Totalmente de acuerdo”), se alcanzó 100 % en aplicabilidad, límite de dominio, memoria y usabilidad; un 92,3 % en validez técnica y claridad; y un 84,6 % en transcripción de voz.
La validación demostró su factibilidad como asistente técnico en el cultivo de banano, lo que sugiere su potencial aplicabilidad en otros cultivos agrícolas. Esto sienta las bases para la implementación de proyectos similares en el contexto agrícola, permitiendo pilotos a mayor escala con indicadores de adopción e impacto productivo.
FINANCIAMIENTO
No Monetario.
AGRADECIMIENTO
A todos los actores sociales involucrados en el desarrollo de la investigación.
REFERENCIAS CONSULTADAS
Ariyo Okaiyeto, S., Bai, J., Wang, J., Mujumdar, A., Xiao, H. (2025). Success of DeepSeek and potential benefits of free access to AI for global-scale use. International Journal of Agricultural and Biological Engineering, 18(1), 304-306. https://doi.org/10.25165/j.ijabe.20251801.9733
Becerra-Encinales, J. F., Bernal-Hernandez, P., Beltrán-Giraldo, J. A., Cooman, A. P., Reyes, L. H., y Cruz, J. C. (2024). Agricultural Extension for Adopting Technological Practices in Developing Countries: A Scoping Review of Barriers and Dimensions. Sustainability, 16(9), 3555. https://doi.org/10.3390/su16093555
Boros, A., Szólik, E., Desalegn, G., y Tőzsér, D. (2025). A Systematic Review of Opportunities and Limitations of Innovative Practices in Sustainable Agriculture. Agronomy, 15(1), 76. https://doi.org/10.3390/agronomy15010076
Caffaro, F., y Rizzo, G. (2024). Knowledge-Enhanced Conversational Agents. Journal of Computer Science and Technology, 39(3), 585-609. https://doi.org/10.1007/s11390-024-2883-4
Calvo-Valverde, L.-A., Rojas-Salazar, K., Hidalgo-Rodríguez, J. F., Mora, V., Sandoval, J. A., Bolaños-Céspedes, E., & Quirós, C. (2023). Un estudio de tecnologías sobre agentes conversacionales para la asistencia de agricultores del plátano. Revista Tecnología En Marcha, 36(4), 3-18. https://doi.org/10.18845/tm.v36i4.6242
Coggins, S., Munshi, S., Smith, J., Yadav, A. K., Poonia, S. P., Patil, S., Singh, N. K., Sawarn, A., Ireland, D. C., McDonald, A. J., Singh, D. K., Sherpa, S. R., y Craufurd, P. (2025). How do chat apps support the use of farming videos in agricultural extension: A case study from Bihar, India. NJAS: Impact in Agricultural and Life Sciences, 97(1), 2420803. https://doi.org/10.1080/27685241.2024.2420803
Esguera, J. G., Balendres, M. A., Paguntalan, D. P. (2024). Overview of the Sigatoka leaf spot complex in banana and its current management. Tropical Plants, 3(1). https://doi.org/10.48130/tp-0024-0001
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., y Wang, H. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv. https://doi.org/10.48550/ARXIV.2312.10997
Graham, C., y Roll, N. (2024). Evaluating OpenAI’s Whisper ASR: Performance analysis across diverse accents and speaker traits. JASA Express Letters, 4(2), 025206. https://doi.org/10.1121/10.0024876
Guamán-Rivera, S. A. (2022). Desarrollo de Políticas Agrarias y su Influencia en los Pequeños Agricultores Ecuatorianos. Revista Científica Zambos, 1(3), 15-28. https://doi.org/10.69484/rcz/v1/n3/30
Gupta, S., Ranjan, R., y Singh, S. N. (2024). A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions. arXiv. https://doi.org/10.48550/ARXIV.2410.12837
Ibrahim, A., Senthilkumar, K., y Saito, K. (2024). Evaluating responses by ChatGPT to farmers’ questions on irrigated lowland rice cultivation in Nigeria. Scientific Reports, 14(1), 3407. https://doi.org/10.1038/s41598-024-53916-1
Kim, T.-S., John Ignacio, M., Yu, S., Jin, H., y Kim, Y.-G. (2024). UI/UX for Generative AI: Taxonomy, Trend, and Challenge. IEEE Access, 12, 179891-179911. https://doi.org/10.1109/ACCESS.2024.3502628
Klesel, M., y Wittmann, H. F. (2025). Retrieval-Augmented Generation (RAG). Business & Information Systems Engineering, 67(4), 551-561. https://doi.org/10.1007/s12599-025-00945-3
Korir, M. K., Mwangi, W., y Kimwele, M. W. (2023). Artificial Intelligence-Based Chatbot Model Providing Expert Advice to Potato Farmers in Kenya. 2023 IEEE AFRICON, 1-6. https://doi.org/10.1109/AFRICON55910.2023.10293557
Kuska, M. T., Wahabzada, M., y Paulus, S. (2024). AI for crop production – Where can large language models (LLMs) provide substantial value? Computers and Electronics in Agriculture, 221, 108924. https://doi.org/10.1016/j.compag.2024.108924
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., y Kiela, D. (2021, abril). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv. https://doi.org/10.48550/arXiv.2005.11401
Lubawa, A. R., Nyambo, D. G., Mduma, N., y Sinde, R. (2025). A Response-by-Retrieval Chatbot for Enhancing Horticulture Extension Services in Tanzania. Engineering, Technology y Applied Science Research, 15(5), 27703-27709. https://doi.org/10.48084/etasr.12761
Munhoz, T., Vargas, J., Teixeira, L., Staver, C., y Dita, M. (2024). Fusarium Tropical Race 4 in Latin America and the Caribbean: Status and global research advances towards disease management. Frontiers in Plant Science, 15. https://doi.org/10.3389/fpls.2024.1397617
Peñalver-Higuera, M. J., Rodríguez-Alegre, L. R., López-Padilla, R. D. P., y Isea-Argüelles, J. J. (2025). Ingeniería de prompts en la industria 4.0: Optimización y automatización inteligente de procesos industriales. Ingenium et Potentia, 7(12), 35–49. https://doi.org/10.35381/i.p.v7i12.4438
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., y Sutskever, I. (2022, diciembre). Robust Speech Recognition via Large-Scale Weak Supervision. arXiv. https://doi.org/10.48550/arXiv.2212.04356
Romero-García, C. V., Saraguro-Reyes, C. M., Mazon-Olivo, B. E., y Morocho-Román, R. F. (2025). Agricultura de precisión en la producción de banano. Revisión sistemática. Ingenium et Potentia, 7(12), 50-76. https://doi.org/10.35381/i.p.v7i12.4450
Samuel, D. J., Skarga-Bandurova, I., Sikolia, D., y Awais, M. (2025). AgroLLM: Connecting Farmers and Agricultural Practices through Large Language Models for Enhanced Knowledge Transfer and Practical Application. arXiv. https://doi.org/10.48550/ARXIV.2503.04788
Sapkota, R., Qureshi, R., Usman Hadi, M., Zohaib Hassan, S., Sadak, F., Shoman, M., Sajjad, M., Ali Dharejo, F., Paudel, A., Li, J., Meng, Z., Shutske, J., y Karkee, M. (2025). Multi-Modal LLMs in Agriculture: A Comprehensive Review. IEEE Transactions on Automation Science and Engineering, 22, 22510-22540. https://doi.org/10.1109/TASE.2025.3612154
Singh, N., Wang’ombe, J., Okanga, N., Zelenska, T., Repishti, J., K, J. G., Mishra, S., Manokaran, R., Singh, V., Rafiq, M. I., Gandhi, R., y Nambi, A. (2024). Farmer.Chat: Scaling AI-Powered Agricultural Services for Smallholder Farmers. arXiv. https://doi.org/10.48550/ARXIV.2409.08916
Spielman, D., Lecoutere, E., Makhija, S., y Van Campenhout, B. (2021). Information and Communications Technology (ICT) and Agricultural Extension in Developing Countries. Annual Review of Resource Economics, 13(1), 177-201. https://doi.org/10.1146/annurev-resource-101520-08065
©2026 por los autores. Este artículo es de acceso abierto y distribuido según los términos y condiciones de la licencia Creative Commons Atribución-NoComercial-CompartirIgual 4.0 Internacional (CC BY-NC-SA 4.0) (https://creativecommons.org/licenses/by-nc-sa/4.0/).